Les méthodes de provisionnement permettent d’utiliser des informations sur les sinistres que ne permettent pas les méthodes agrégées. Elles sont particulièrement intéressantes pour des sinistres complexes au déroulement volatil, comme les sinistres graves.
La méthode proposée ici ne se substitue pas aux méthodes traditionnelles. Elle enrichit les outils actuels d’estimation des provisions en ajustant les biais d’observation des sinistres longs et coûteux.
Provisionnement individuel : un cadre théorique solide
Les travaux présentés dans cet article s’inspirent directement de l’étude « Tree-based censored regression with applications in insurance » par O. Lopez, X. Milhaud et P. Thérond. Cette étude présente les bases d’une modélisation des sinistres en tenant compte des données censurées. Les données censurées désignent ici les sinistres qui sont toujours en cours de traitement au moment de l’observation.
Cette approche permet de mieux cerner les spécificités des sinistres individuels, tout en corrigeant les biais dus aux sinistres non liquidés, notamment en matière de sinistres longs ou coûteux.
Modélisation des variables explicatives
La méthode repose sur la modélisation de l’impact des variables explicatives X sur le coût total d’un sinistre M et sa durée de vie T. Elle s’appuie sur une fonction de perte, minimisée pour prédire ces deux paramètres à partir des données disponibles.
Cependant, en assurance, les données de sinistres présentent fréquemment de la censure. C’est-à-dire que certaines informations sont partiellement observées, en particulier pour les sinistres à long développement.
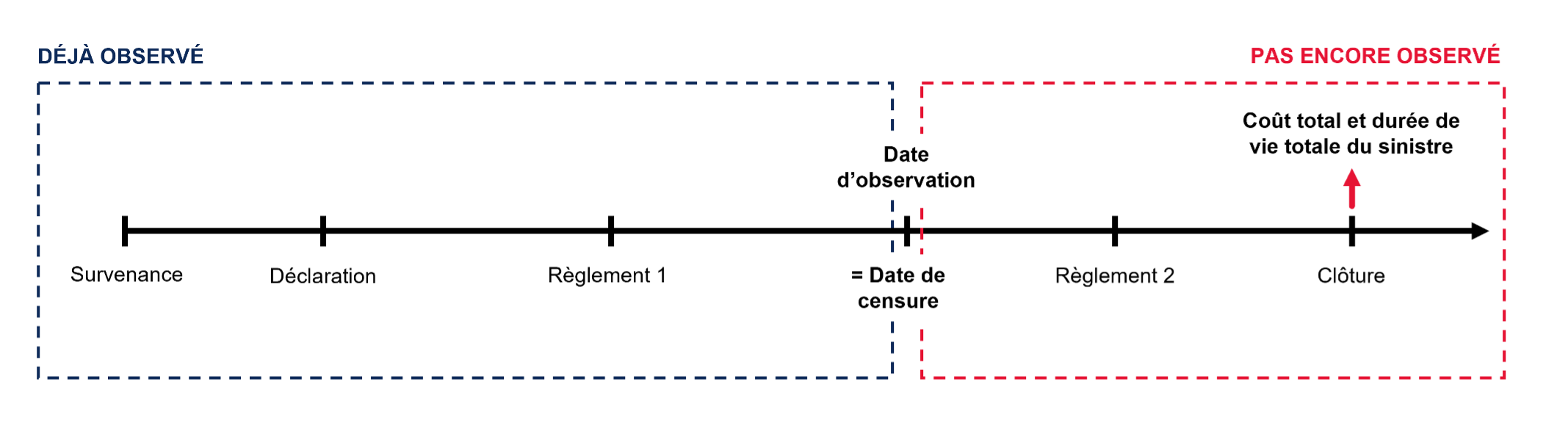
Pour remédier à cela, la méthode utilise des poids calculés via l’estimateur de Kaplan-Meier. Ces poids permettent de surmonter deux contraintes liées à la censure des données.
Premièrement, ils rendent possible l’estimation de la fonction de répartition F(M,T,X), même lorsque les observations sont incomplètes.
Deuxièmement, ils corrigent les biais dus à la sous-représentation des sinistres longs dans les bases de données non censurées. En effet, les sinistres de longue durée sont généralement moins représentés que les sinistres courts dans les données des assureurs. À un instant t donné, un sinistre long a davantage de chances de ne pas être entièrement liquidé et donc d’être censuré.
En attribuant un poids plus élevé aux sinistres longs dans les données d’apprentissage, ces poids permettent de compenser ce biais, améliorant ainsi la précision des estimations.
Mise en œuvre avec l’algorithme CART
Concrètement, l’algorithme CART (Classification and Regression Trees) est utilisé pour segmenter les sinistres en groupes homogènes en fonction des variables explicatives X.
Adapté aux données censurées grâce aux pondérations de Kaplan-Meier, cet algorithme permet de modéliser la relation entre les caractéristiques propres du sinistre, telles que le délai de déclaration du sinistre ou encore le type de véhicule, et sa vie (ici représentée par sa durée de vie ou son coût total).
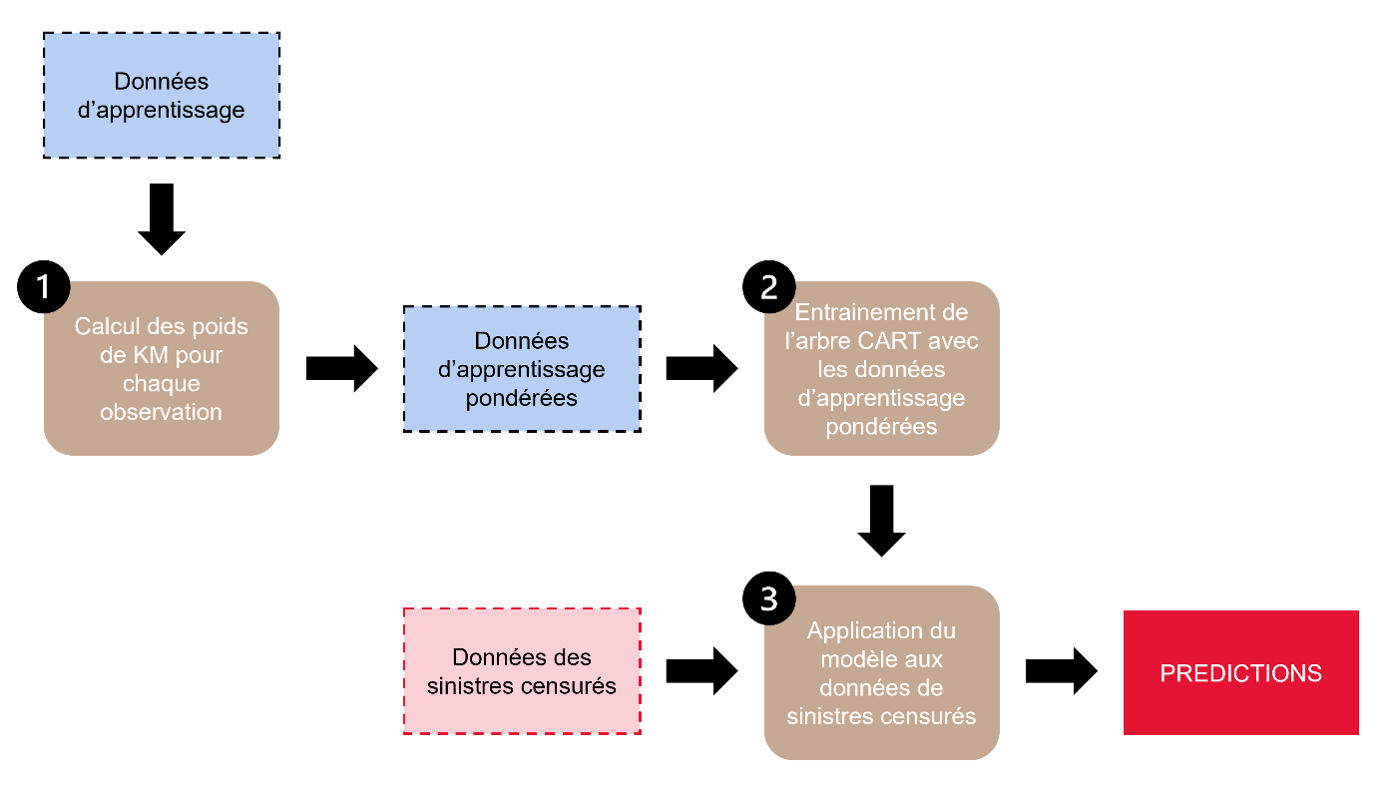
Cette approche permet une meilleure prise en compte des sinistres longs ou coûteux, tout en corrigeant les effets des données partiellement observées.
Application de la méthode à des données de sinistres de dommage automobile
Nous illustrons l’approche sur un portefeuille de 15 000 sinistres de dommages matériels aux véhicules clôturés durant une année N et déclarés avant le 31/12/N-1. En appliquant la méthode décrite ci-dessus pour prédire la durée de vie résiduelle ainsi que le coût total des sinistres, nous obtenons les résultats suivants :
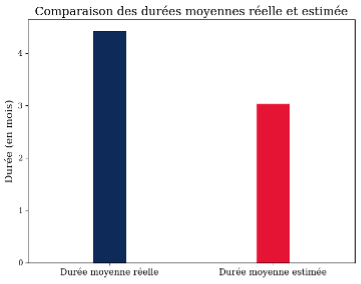
La comparaison entre la durée moyenne réelle et la durée moyenne estimée montre que le modèle estime de manière assez cohérente la durée moyenne d’un sinistre. Avec une prévision de 3,2 mois contre une réalité de 4 mois, la différence reste néanmoins notable car les durées comparées sont courtes. La précision du modèle pourrait encore être améliorée en intégrant davantage de variables temporelles ou contextuelles, mais les résultats actuels témoignent déjà d’une bonne capacité de prévision du modèle.
Le modèle montre également une bonne capacité à capturer les grandes tendances relatives aux coûts des sinistres.
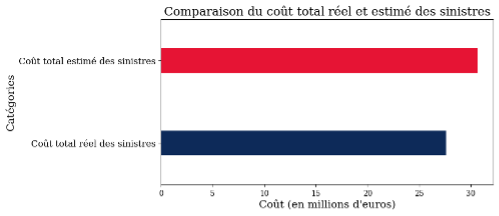
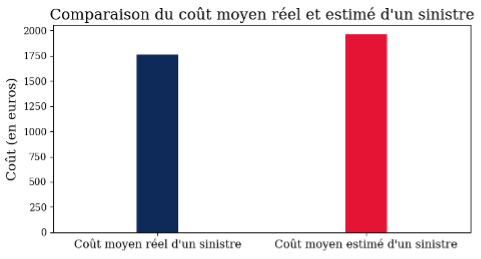
Le modèle a tendance à surestimer, mais parvient tout de même à estimer de manière assez cohérente le coût global des sinistres (environ 27 millions d’euros pour le réel contre 30 millions d’euros estimés) ainsi que leur coût moyen (1763 euros pour le réel contre 1960 euros estimés). Bien que l’estimation globale soit satisfaisante, les résultats individuels présentent parfois des écarts significatifs par rapport à la réalité. Les prédictions individuelles sont en effet très sensibles à la disponibilité et à la qualité des données, notamment au nombre de variables explicatives disponibles.
Les résultats obtenus à partir de la méthode de modélisation montrent un potentiel intéressant, mais aussi certaines limites qu’il convient de souligner pour une compréhension plus fine des performances du modèle.
Limites de la méthode de provisionnement individuel par CART pondéré
Première limite : la méthode reste sensible à la qualité et à la disponibilité des données, qui influencent fortement la précision des estimations, notamment pour les sinistres à long développement. La complexité de sa mise en œuvre, en raison des calculs intensifs, constitue également un défi opérationnel.
Deuxième limite : l’algorithme CART peut souffrir de surapprentissage, surtout en présence de relations complexes entre les variables explicatives, nécessitant des ajustements réguliers, comme la taille des arbres.
Enfin, les hypothèses strictes concernant la censure des données et la dépendance à l’estimateur de Kaplan-Meier peuvent introduire des biais si elles ne sont pas respectées.
Provisionnement individuel : des difficultés de mise en œuvre
Ces limites soulignent des enjeux plus globaux dans le secteur assurantiel :
- La qualité et la disponibilité des données constituent un défi récurrent pour toutes les méthodes de provisionnement, tout comme les difficultés opérationnelles liées à la mise en place de modèles plus complexes.
- L’intégration de techniques avancées, telles que les forêts aléatoires ou les réseaux de neurones, soulève également la question de l’équilibre entre la précision des estimations et la faisabilité opérationnelle.
- Surmonter les limites de cette méthode répond donc à un besoin plus large d’amélioration continue des estimations dans un contexte de croissance en matière de données et de capacités de calcul.
La méthode CART pondéré en complément des approches traditionnelles
La méthode proposée apporte un éclairage nouveau sur le provisionnement individuel, permettant une gestion plus spécifique des sinistres censurés. En ajustant les biais associés aux sinistres longs et coûteux, elle contribue à fournir des estimations plus fines et peut donc trouver sa place, en complément des outils actuels, pour affiner les estimations de provisions.
Cette démarche s’inscrit pleinement dans l’évolution du provisionnement, en offrant des solutions plus adaptées aux défis que rencontrent aujourd’hui les acteurs du secteur assurantiel.