Qu’est-ce que le web scraping ?
Le web scraping permet d’extraire des données d’un site web. La démarche consiste à prélever automatiquement les données non structurées d’un site web et à les stocker dans une base de données exploitable au format de son choix.
Les solutions de web scraping
Des outils low-code comme Apify, Octoparse, ou Parsehub existent. Ces solutions sont souvent payantes. Le langage python propose plusieurs librairies capables de requêter sur des pages web :
- Requests est capable de récupérer de l’information statique pour lesquelles il ne nécessite pas d’action utilisateur ;
- Selenium, BeautifulSoup, et Scrapy sont des librairies populaires de web scraping qui permettent de récupérer de l’information qui nécessitent une action utilisateur.
Le cadre légal
En l’absence de réglementation spécifique, le cadre légal du web scraping demeure une zone floue. Son usage doit néanmoins respecter la législation, qui protège à la fois les droits des créateurs de bases de données, des usagers et des données personnelles. En particulier, le respect des droits d’auteur, en protégeant des producteurs de base de données, impose une utilisation mesurée des extractions de données, en quantité, en fréquence et en ciblage. Le droit des contrats invite à consulter les Conditions générales d’utilisation (CGU) des sites internet considérés pour vérifier si l’extraction de données est permise. Le droit de la protection des données veille par ailleurs au respect du caractère personnel de la donnée, au travers du règlement RGPD. Enfin, le droit de la concurrence prohibe le « parasitisme » ou la « concurrence déloyale ».
Un usage averti du web scraping via des précautions d’usage et une réflexion sur le caractère éthique de son objectif sont par conséquent essentiels afin de garantir un respect du site et une protection de son activité face à des recours judiciaires.
Avant d’entreprendre un projet de web scraping
Des étapes en amont de l’écriture du code sont nécessaires :
- Evaluer le temps d’exécution. Il est possible que le jeu n’en vaille pas la chandelle. Avant de se lancer, deux questions à se poser : le besoin est-il ponctuel ou récurrent ? Quelle est la plus-value potentielle des données dans l’activité ?
- Identifier l’ensemble des solutions capables potentiellement de récupérer les données recherchées. Parfois, les sites web mettent à disposition leur API qui offrent des possibilités plus larges, faciles et rapides ;
- Vérifier les autorisations que la page internet énonce dans son fichier robots.txt. Pour le retrouver : écrire l’url de la page suivie de « /robots.txt ». Ce fichier énonce les droits d’exploration que le site confère aux robots des moteurs de recherche comme Googlebot. Il fournit ainsi une bonne indication du droit de récupération des données d’un site. Si l’url avec robots.txt renvoie une erreur 404, cela signifie que le site ne possède pas de « robots.txt » ;
- Définir son input : il est parfois nécessaire de constituer un ensemble d’inputs pour récupérer les résultats du site à explorer.
- Définir son output : quel format, quels champs, quel mode de remplissage ?
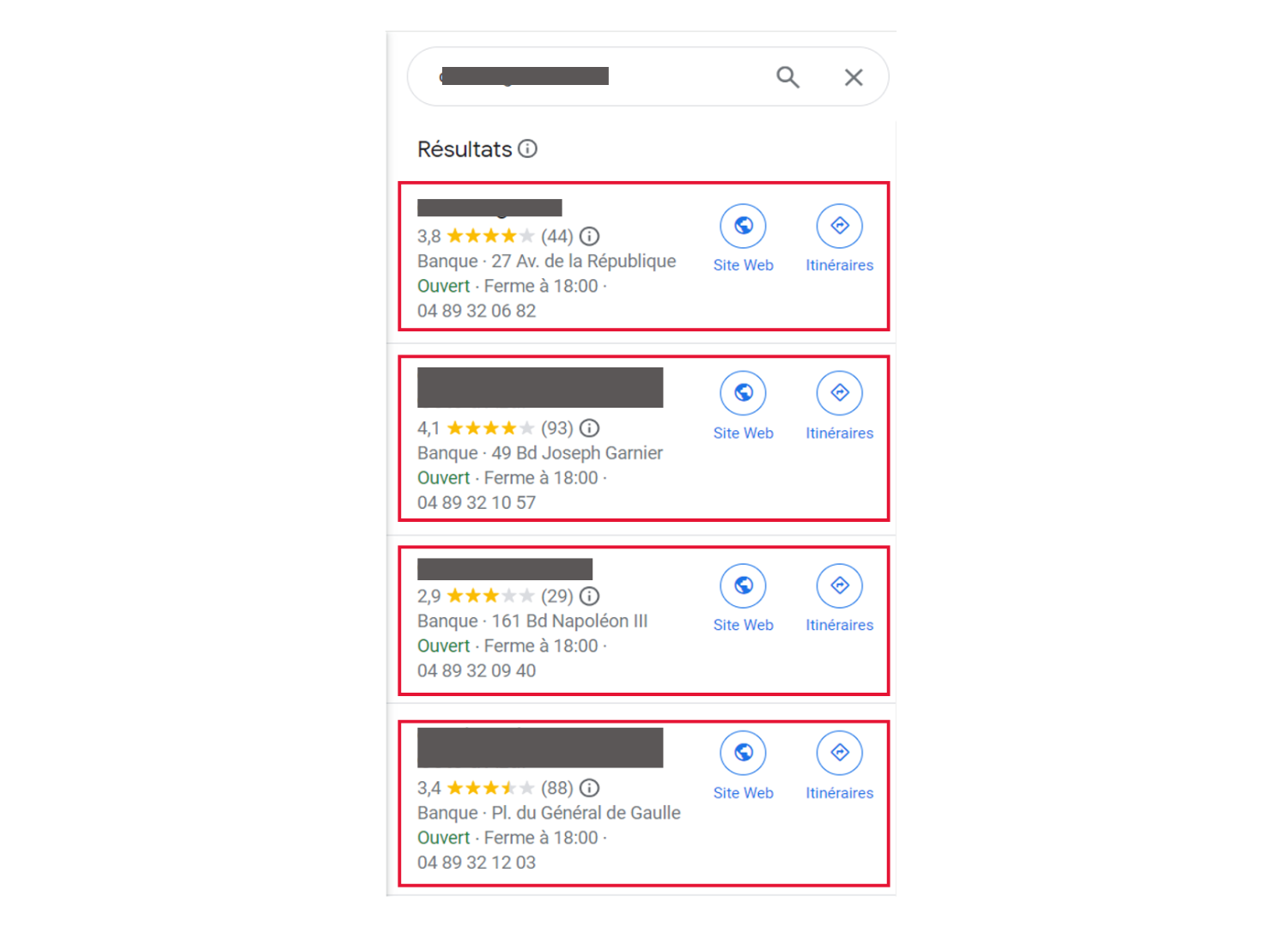
Exemple de cas d’usage : créer un outil de gestion des avis google maps.
Objectifs métier :
- Fournir un état des lieux statistique de la satisfaction des clients sur les agences d’un réseau, bancaire par exemple ;
- Indiquer des thématiques problématiques ou porteuses pour les clients ;
- Améliorer la stratégie de gestion des avis ;
- Développer un outil de visualisation capable d’aider les directions relations client à communiquer des directives à leurs réseaux d’agences.
Objectifs techniques :
Il s’agit de constituer une base de données qui recense l’ensemble des avis disponibles sur google maps dans le périmètre défini.
Deux étapes permettent de constituer cette base de données (sous format excel) :
- Récupération d’une liste de l’ensemble des agences (dans google maps) en bouclant sur les recherches du type ‘Banque A in Moselle 57’ sur le périmètre géographique et le panel de banque définis ;
- Récupération des avis sur les agences de la liste obtenue.
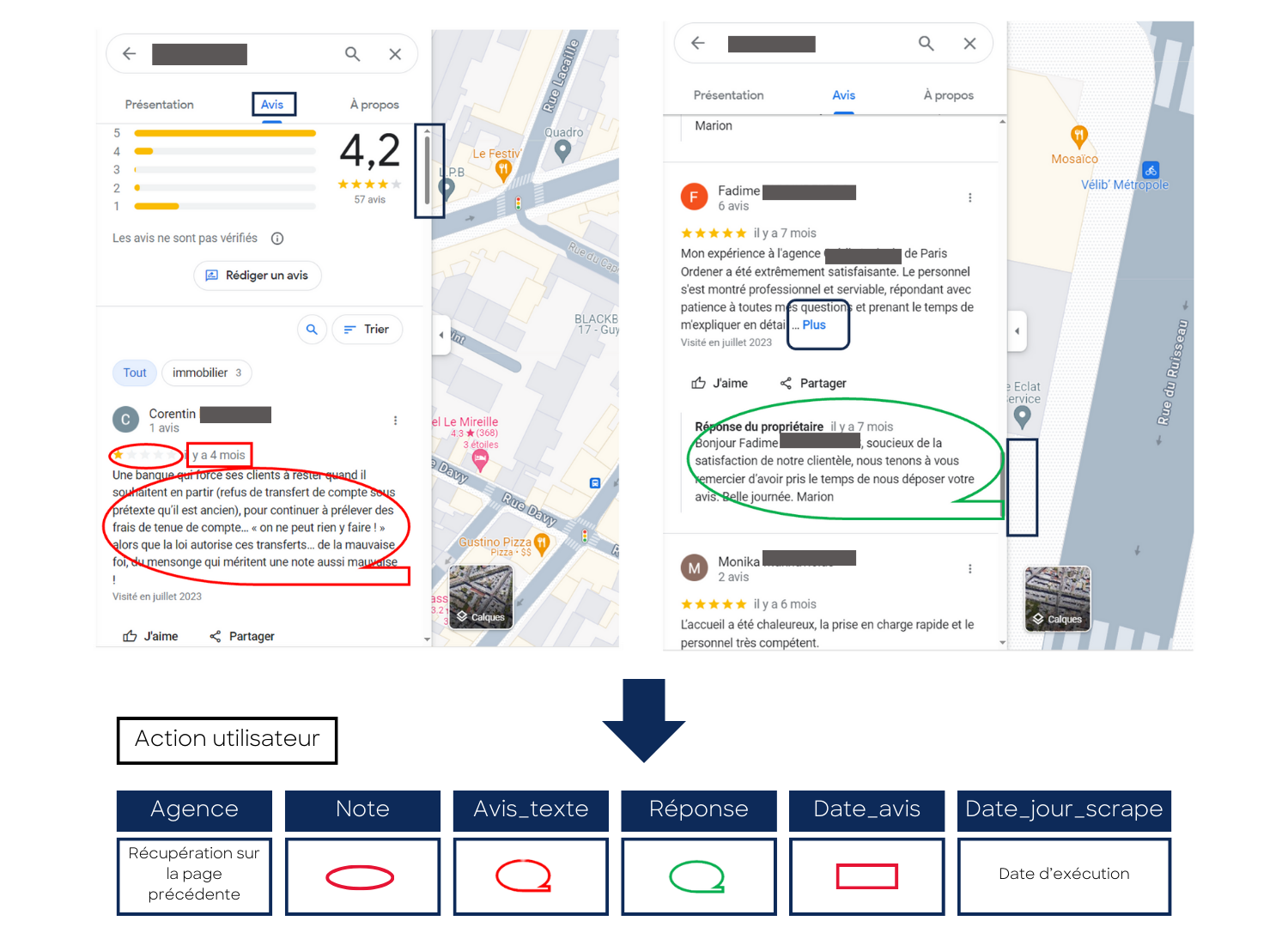
Web scraping : des limites techniques et juridiques
Première limite : l’existence de systèmes de protection. Avec l’essor du web scraping, des systèmes de protection de site web ont été mis en place. En cas d’activité inhabituelle observée sur le site, le système vérifie « l’identité » de ses visiteurs via les adresses IP. Si un IP revient de manière massive, le site web va s’armer de captcha, bloquer l’accès ou même envoyer de fausses informations. Un abus peut dans certains cas aboutir à des poursuites judiciaires. Cet élément pose la question du bon droit de l’action de web scraper.
C’est la deuxième limite, d’ordre juridique. Propriété intellectuelle, droit des contrats… la réglementation et la jurisprudence encadrent les possibilités de récupération des données. Ces garde-fous doivent inciter à privilégier systématiquement d’autres solutions quand elles existent (API, flux RSS notamment).
La troisième limite est technique : le temps d’exécution.
D’autres solutions, telles que l’usage d’API, peuvent se révéler plus rapides. A titre d’exemple sur un cas d’usage similaire : la récupération des notes et des avis des utilisateurs concernant les applications bancaires sur Google Play ou l’App Store est disponible via l’utilisation de librairies python.
[Pour les connaisseurs d’html] Il existe également des moyens pour réduire ce temps d’exécution. Afin de récupérer toutes les informations relatives à des éléments dont le format est commun sur une page, l’identification par classe est préférable plutôt que par id ou xpath.
Par exemple :
Chaque encadré est codé selon la même classe HTML. Il suffit donc de trouver les éléments dont la classe est la même ;
- Utiliser la bibliothèque requests lorsque la récupération de l’information souhaitée ne nécessite pas d’action utilisateur.
Nos recommandations pour une « bonne » stratégie de récupération des données
- Consulter les droits que confère le site internet à ses utilisateurs (robots.txt, protection droits d’auteur e CGU). Il faut également être attentif au caractère éthique de l’objectif de la récupération des données. Nous rappelons qu’un usage de la donnée concurrentielle peut être préjudiciable et considéré comme une concurrence déloyale. Même dans le cas où l’usage du web scraping est accepté, il faut faire en sorte de ne pas « monopoliser » le site internet en minimisant le nombre de requêtes nécessaires, ou en les espaçant ;
- Vérifier s’il existe une technique alternative au scraping permettant de répondre au besoin de données : flux rss, API, Open data, Feedings.
- Privilégier ces techniques, qui permettent d’être dans son bon droit et de bénéficier d’une efficacité et d’une simplicité de récupération des données. Ces techniques peuvent bien sûr avoir un coût (ce n’est pas toujours le cas).